



A remarkable feature of the human brain is its ability to find differences even in enormous amounts of visual information. This feature is very useful when studying large amounts of data. This is because the content of the data must be compressed into a format that human intelligence can understand. For visual analytics, dimensionality reduction remains a major issue.
Scientists from Aalto University and the University of Helsinki, part of the Finnish Center for Artificial Intelligence (FCAI), tested the capabilities of the most well-known visual analytics methods and found that none of them worked when the amount of data increased significantly. . For example, t-SNE, LargeViz, and UMAP methods can no longer distinguish extremely strong signal groups of observations in the data when the number of observations reaches hundreds of thousands. t-SNE, LargeViz and UMAP methods no longer work properly.
Researchers developed a new nonlinear dimensionality reduction method called Stochastic Cluster Embedding (SCE) for better cluster visualization. It aims to visualize data sets as clearly as possible and is designed to visualize data clusters and other macroscopic features in a way that is as clear as possible, easy to observe, and understandable to humans. SCE uses graphics acceleration similar to state-of-the-art artificial intelligence methods for neural network computing.
The discovery of the Higgs boson became the basis for the invention of this algorithm. The dataset for this related experiment contains over 11 million feature vectors. And this data needed convenient, clear visualization. This inspired scientists to develop new methods.
Researchers generalized SNE using an I-divergence series parameterized by a scale factor s between the unnormalized similarity of the input and output spaces. SNE is a special case of the family where s is chosen as a normalization factor for the output similarity. However, during testing, we found that the best value for s for visualizing clusters was often different from the value chosen by SNE. Therefore, to overcome the shortcomings of t-SNE, the new SCE method uses a different approach that mixes input similarities when calculating s. When optimizing a new learning objective, the coefficients are adaptively adjusted so that data points are better clustered. The researchers also developed an efficient optimization algorithm using asynchronous stochastic descent on block coordinates. The new algorithm can use parallel computing devices and is suitable for large-scale tasks with large amounts of data.
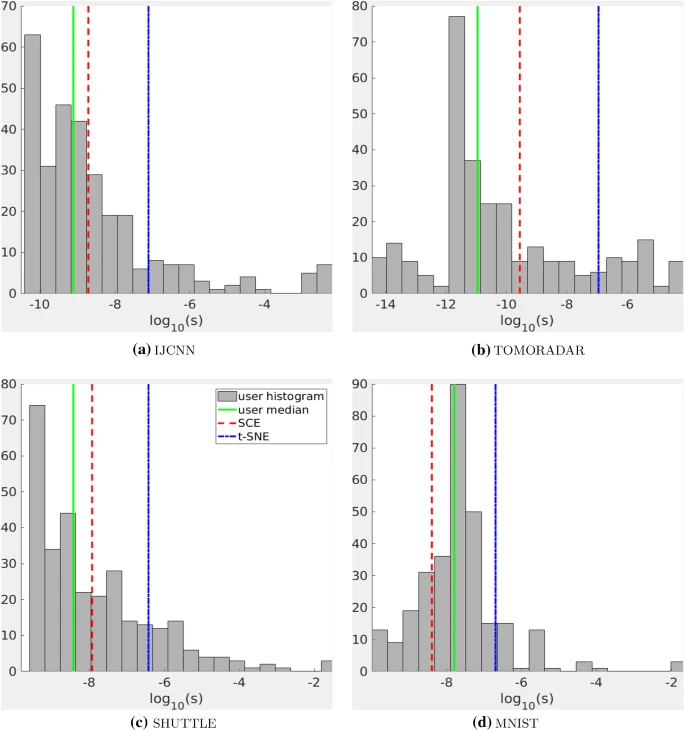
While developing the project, scientists tested the method on a variety of real-world data sets and compared it to other state-of-the-art NLDR methods. Users in the test chose a range of s values for viewing clusters and the visualization that best suited them. The researchers then compared the resulting s values from SCE and t-SNE to see which one was closer to human choices. The four smallest datasets were used for testing: IJCNN, TOMORADAR, SHUTTLE, and MNIST. For each dataset, test participants were presented with a set of visualizations that used sliders to display s values and tested the corresponding precomputed visualizations. Users chose their preferred s value for cluster visualization.
The test results clearly show that the s selected by SNE are to the right of the human median (solid green line) for all datasets. This means that in humans, GSNE with small s is often better than t-SNE for cluster visualization. In contrast, the SCE selection (red dashed line) is closer to the human median in all four data sets.
By applying the Stochastic Cluster Embedding method to the data of the Higgs boson, the most important physical properties were clearly identified. Stochastic Clustering Embedding, a new nonlinear dimensionality reduction method for better cluster visualization, works several times faster than previous methods and is much more stable even in complex applications. We modify t-SNE using an adaptive and efficient trade-off between attraction and repulsion. Experimental results showed that this method can consistently identify internal clusters. Additionally, the scientists provided a simple and fast optimization algorithm that can be easily implemented on modern parallel computing platforms. Efficient software using asynchronous stochastic block gradient descent has been developed to optimize a new family of objective functions. Experimental results show that this method consistently and significantly improves the visualization of data clusters compared to state-of-the-art probabilistic neighborhood embedding approaches.
The code for that method is publicly available on github.