


A team of researchers at New York University has made progress in neural speech decoding, bringing us closer to a future where individuals who have lost the ability to speak can regain their voices.
that much studypublished in Nature Machine Intelligence, presents a new deep learning framework that accurately translates brain signals into understandable speech.
People who have suffered brain damage from stroke, degenerative disease, or physical trauma can use these devices to speak using only their thoughts using a speech synthesizer.
This involves deep learning models that map electrocorticography (ECoG) signals to a set of interpretable speech features such as pitch, loudness, and spectral content of speech sounds.
ECoG data captures the essential elements of speech production and helps the system concisely represent the intended speech.
The second stage involves a neural speech synthesizer that can convert the extracted speech features into an audible spectrogram and then into speech waveforms.
Those waveforms can ultimately be converted into natural synthesized speech.
A new paper came out today @NatMachIntell, where we demonstrate robust neural-to-speech decoding across 48 patients. https://t.co/rNPAMr4l68 pic.twitter.com/FG7QKCBVzp
— Adeen Flinker 🇮🇱🇺🇦🌈️ (@adeenflinker) April 9, 2024
How the research works
The research involves training an AI model that can power a speech synthesizer, allowing people with speech impairments to communicate using only their thoughts.
Here’s how it works in detail:
1. Brain data collection
The first step is to collect the raw data needed to train the speech decoding model. Researchers studied 48 participants who were undergoing neurosurgery for epilepsy.
During the study, participants were asked to read hundreds of sentences out loud while their brain activity was recorded using an ECoG grid.
These grids are placed directly on the brain surface to capture electrical signals from brain regions involved in speech production.
2. Mapping brain signals into speech
Using speech data, the researchers developed a sophisticated AI model that maps recorded brain signals to specific speech characteristics, such as pitch, loudness, and the natural frequencies that make up various speech sounds.
3. Speech synthesis from features
The third step focuses on converting speech features extracted from brain signals back into audible speech.
The researchers used a special speech synthesizer that takes the extracted features and creates a spectrogram, a visual representation of the speech sound.
4. Results evaluation
The researchers compared the voices produced by the model with the original voices spoken by the participants.
They measured the similarity between the two using objective indicators and found that the generated speech closely matched the content and rhythm of the original.
5. Test new words
To determine whether the model could handle new words that had never been seen before, we intentionally omitted certain words during the model training phase and then tested the model’s performance on these unseen words.
The model’s ability to accurately decode even novel words demonstrates its potential to generalize and process a variety of speech patterns.
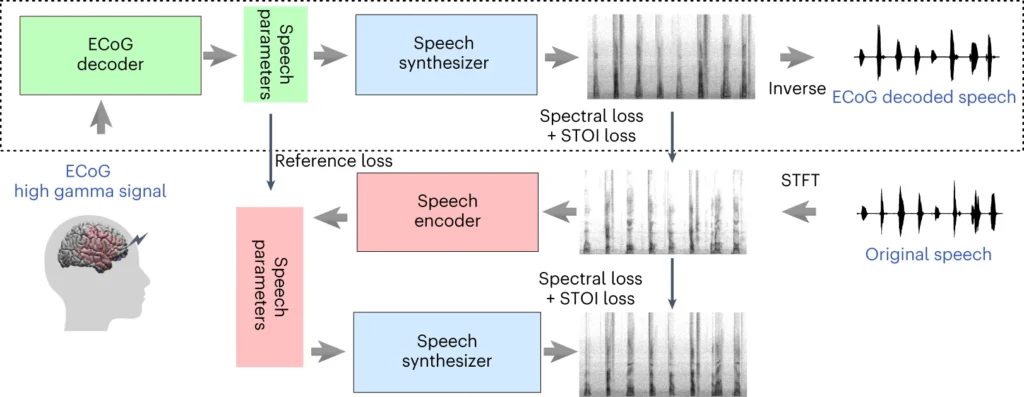
The top part of the diagram above describes the process of converting brain signals into speech. First, the decoder converts these signals into speech parameters over time. The synthesizer then creates a sound picture (spectrogram) from these parameters. Another tool changes these pictures back into sound waves.
The bottom section describes a system that helps train brain signal decoders by imitating speech. It takes a sound picture, converts it to speech parameters, and then uses it to create a new sound picture. This part of the system learns from actual speech sounds to make improvements.
After training, only top-level processes are needed to convert brain signals into speech.
One of the key advantages of the NYU approach is that high-quality speech decoding can be achieved without the need for ultra-high-density electrode arrays, which are not suitable for long-term implantation.
Essentially, this is a lighter and more portable solution.
Another notable achievement was the successful decoding of speech in both the left and right hemispheres of the brain. This is important for patients who have brain damage on one side of the brain.
Transform thoughts into words using AI
The NYU study builds on previous research in neural speech decoding and brain-computer interfaces (BCIs).
In 2023, a team from the University of California, San Francisco, discovered that a paralyzed stroke survivor was create a sentence It progresses at a speed of 78 words per minute using BCI, which synthesizes both vocalizations and facial expressions of brain signals.
Other recent research has explored using AI to interpret various aspects of human thinking through brain activity. Researchers have demonstrated the ability to generate images, text, and even music from fMRI and EEG data.
for example, Study at the University of Helsinki EEG signals were used to guide a generative adversarial network (GAN) to generate facial images that matched the participants’ thoughts.
Meta AI too developed technology It uses non-invasively collected brain waves to decipher what someone is hearing.
However, thoughts alone did not come close to predicting speech.
opportunities and challenges
NYU’s method is more accessible because it uses electrodes that are more widely available and clinically viable than past methods.
These advances are exciting, but major hurdles must be overcome before mind-reading AI can be widely applied.
First, collecting high-quality brain data requires extensive training of machine learning models, and individual differences in brain activity can make generalization difficult.
Nonetheless, the NYU study represents progress in this direction by demonstrating high-precision speech decoding using a lighter ECoG array.
Going forward, the NYU team aims to improve the model for real-time speech decoding to get closer to the ultimate goal of enabling natural, fluent conversations for individuals with speech impairments.
They also plan to adapt the system to include a fully implantable wireless device that can be used in everyday life.