


Processing long documents with precision was a huge challenge. Generative transformer models have been at the forefront of analyzing and understanding a wide range of texts. Having documents spread across tens of thousands of tokens reduces efficiency and exposes gaps in current methodology. These limitations highlight the need to explore the complexity of a wide range of texts without sacrificing accuracy or efficiency.
Recent breakthroughs in augmenting pretrained language models with circular memory represent a significant leap forward. Differing from traditional benchmarks that go beyond sequences of 104 elements, this method demonstrates the ability to handle tasks involving sequences of up to 107 elements. This advancement not only sets a new precedent for the size of input sequences that neural networks can handle, but also paves the way for models to explore more complex and realistic scenarios.
Researchers from AIRI Moscow, Neural Networks and Deep Learning Lab MIPT, and the London Institute for Mathematical Sciences introduce BABILong, a pioneering benchmark meticulously crafted to evaluate the ability of NLP models to analyze long documents. BABILong intricately weaves simple episodic facts within a collection of book texts to create complex haystack scenarios. This benchmark examines up to 10 million tokens to test the model’s ability to find and exploit relevant information hidden in a sea of data. This difficult task challenges even the most advanced models to demonstrate their ability to effectively process and understand long documents.
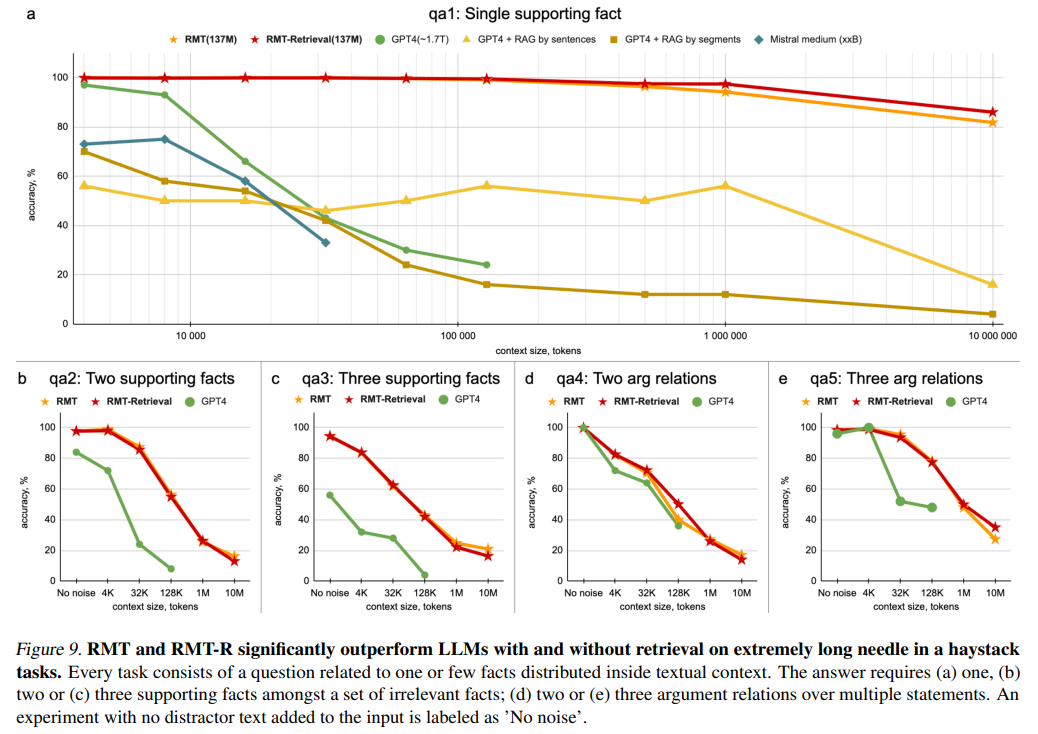
Evaluating different models against the BABILong benchmark revealed notable performance differences. As a smaller generation model, GPT-2, when fine-tuned through circular memory expansion, outperforms its counterparts, including the more sophisticated GPT-4 and the Retrieval-Augmented Generation (RAG) model. These fine-tuning allows GPT-2 to adeptly handle sequences extending up to 10 million tokens, demonstrating unprecedented proficiency in handling long sequences.
These methodological innovations redefine the parameters of possibility within the field. By incorporating circular memory, these models can now handle long documents in ways that were previously considered infeasible. These developments have the potential to have profound implications for the future of NLP, opening new avenues for research and applications that were once out of reach.
In conclusion, exploring and implementing recursive memory extensions to transformer models represents a pivotal advancement in NLP. Highlights of this development include:
- The introduction of a new benchmark, BABILong, addresses an important need for a tool that can rigorously evaluate the performance of NLP models on long documents.
- Fine-tuning GPT-2 through iterative memory augmentation has proven to be a game changer, dramatically improving the model’s ability to process and understand documents containing up to 10 million tokens.
- This breakthrough demonstrates the potential of enriching models with circular memory and paves the way for developing more sophisticated and capable NLP applications.
Please confirm paper. All credit for this study goes to the researchers of this project. Also, don’t forget to follow us Twitter and google news. join Over 38,000 ML SubReddits, 41,000+ Facebook communities; discord channeland LinkedIn GrWhoop.
If you like our work, you will love us Newsletter..
Don’t forget to join us telegram channel
You may also like us Free AI course…
![]()
Hello, my name is Adnan Hassan. I am working as a consulting intern at Marktechpost and will soon be a management trainee at American Express. I am currently pursuing a dual degree from the Indian Institute of Technology, Kharagpur. I have a passion for technology and want to create new products that make a difference.
🚀 LLMWare launches SLIM: Compact special function call model for multi-step automation [Check out all the models]