


The effective de-identification algorithms that balance data usage and privacy are critical. Industries like healthcare, finance, and advertising rely on accurate and secure data analysis. However, existing de-identification methods often compromise either the data usability or privacy protection and limit advanced applications like knowledge engineering and AI modeling.
To address these challenges, we introduce High Fidelity (HiFi) data, a novel approach to meet the dual objectives of data usability and privacy protection. High-fidelity data maintains the original data’s usability while ensuring compliance with stringent privacy regulations.
Firstly, the de-identification approaches and their strengths and weaknesses are examined. Then four fundamental features of HiFi data are specified and rationalized: visual integrity, population integrity, statistical integrity, and ownership integrity. Lastly, the balancing of data usage and privacy protection is discussed with examples.
Current Status of De-Identification
De-identification is the process of reducing the informative content in data to decrease the probability of discovering an individual’s identity. The growing use of personal information for extended purposes may introduce more risk of privacy leakage.
Various metrics and algorithms have been developed to de-identify data. HHS published a detailed guide, “Guidance Regarding Methods for De-identification of Protected Health Information in Accordance with the Health Insurance Portability and Accountability Act (HIPAA) Privacy Rule,” known as Safe Harbor, to measure de-identified patient health records. Common de-identification approaches are as follows:
Redaction and Suppression
This approach involves removing certain data elements from database records.
- A common difficulty with these approaches is to define “done properly.”
- Removal of elements can significantly impact the effective use of data and possible loss of critical information for analysis.
Blurring
Blurring is reducing the data precision by combining several data elements. Three main approaches are:
- Aggregation: Combining individual data points into larger groups (e.g., summarizing data by region instead of individual address)
- Generalization: Replacing specific data with broader categories (e.g., replacing age with age range)
- Pixelation: Lowering the resolution of data (e.g., less precise geographic coordinates)
Blurring methods are used in various reports or statistical summaries to provide a level of anonymity without fully protecting individual data rather than general-purpose de-identification.
Masking
Masking involves replacing data elements with either random or made-up value, or with another value in the dataset. It may decrease the accuracy of computations in many cases, affecting the validity and usability. The main variants in this category include:
- Pseudonymization: Assigning pseudonyms to data elements to mask their original values while maintaining consistency across the dataset
- Perturbation randomization: Adding random noise to data elements to mask their true values without completely distorting the overall dataset
- Swapping/Shuffling: Exchanging values between records to mask identities while preserving the dataset’s statistical properties
- Noise differential privacy: Injecting statistical noise into the data to protect privacy while allowing for meaningful aggregate analysis
High Fidelity Data: What and Why
There are several key needs for HiFi Data, including but not limited to:
- Privacy and regulatory compliance: Ensuring data privacy and adhering to associated regulations
- Safe data utilization: Discover business insight without risking privacy.
- AI modeling: Train AI models with real-world data for better and more accurate behavior of the model itself and agents.
- Rapid data access for production issues: Access to production quality data during issues or unexpected network traffic without compromising privacy
Given these complex and multifaceted requirements, a breakthrough solution is necessary that ensures:
- Privacy protection: Privacy and sensitive data is encoded to prevent privacy leaks.
- Data integrity: The transformed data retains the same structure, size, and logical consistency as the original data.
- Usage for analysis and AI: For analysis, projections, and AI modeling, the transformation should preserve statistical characteristics and population properties ideally in a lossless fashion.
- Quick access: Transforming should be quick and on-demand-based to ensure the transformation is accessible for production issues.
High Fidelity Data Specification
High Fidelity Data refers to data that is faithfulness to original features after transformation and/or encoding, including:
- Visual integrity: The transformed data retains its original format, making it “look and feel” the same as the original ones (e.g., dates still appear as dates, phone numbers as phone numbers).
- Population integrity: The transformed data preserves the population characteristics of the original dataset, ensuring that the distribution and relationships within the data remain intact.
- Statistical integrity: The statistical properties are maintained, ensuring that analyses performed on the encoded data yield results similar to those on the original data.
- Ownership integrity: The data retains information about its origin, ensuring that the ownership and provenance of the data are preserved to avoid unnecessary extended use.
High Fidelity Data maintains privacy, usability, and integrities, making it suitable for data analysis, AI modeling, and reliable deployment by testing of production quality data.
Visual Integrity
Visual Integrity means the transformed data should comply with the original data in ways:
- Length of words and phrases: Transformations should maintain the original length of the data. For instance, Base64 or AES encrypted names would make them 15-30% longer, which is undesirable.
- Data types: Data types should be preserved (e.g., phone numbers should remain as dashed digital characters). The last four digits extracted as integers would break or change the validation pipeline.
- Data format: Remain consistent with the original
- Internal structure of composite data: Complex data types, like addresses, should maintain their internal structure.
Although visual integrity might not seem significant at first glance, it profoundly impacts how analysts use the data and how trained LLMs predict outcomes.
As shown in the following HiFi Data Visual Integrity:
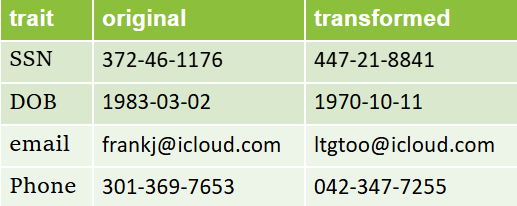
- Transformed birthdates still appear as dates.
- Transformed phone numbers or SSNs still resemble phone numbers or SSNs, rather than random strings.
- Transformed emails look like valid email addresses but cannot be looked up on a server. No need for popular domains like “Gmail” to encode, but for less common domains, the domain is encoded as well.
Visual integrity is critical in complex software ecosystems, especially production environments. Changes in data type and length could cause database schema changes, which are labor-intensive, time-consuming, and error-prone. Validation failures during QA could restart development sprints, and may even trigger configuration changes in firewalls and security monitoring systems. For instance, invalid email addresses or phone numbers might trigger security alerts.
Preserving the “Look & Feel” of data is essential for data engineers and analysts, leading to less error-prone insights.
Population Integrity
Population integrity ensures the consistency of report and summary statistics is maintained in a lossless fashion before and after transformation.
- Population distributions: The transformed data should mirror the original data’s population distribution (e.g., in healthcare, the percentage of patients from different states should remain consistent).
- Correlations and relations: The internal relationships and correlations between data elements should be preserved which is crucial for analyses that rely on understanding the interplay between different variables. For example, if one “John” had 100 records in the database, after transforming, there would still be 100 records of “John”, with each “John” represented only once.
Maintaining population integrity is essential to ensure the transformed data remains useful for statistical analysis and modeling for these reasons:
- Accurate analysis: Analysts can rely on the transformed data to provide the same insights as the original data, ensuring that trends and patterns are correctly discovered.
- Reliable data linkage: Encoded data can still be linked across different datasets without loss of information, allowing for comprehensive analyses that require data integration.
- Consistent results: Ensures that the results of data queries and analyses are consistent with what would be obtained from the original dataset
In healthcare, maintaining population integrity ensures accurate tracking of patient records and health outcomes even after data de-identification. In finance, it enables precise analysis of transaction histories and customer behavior without compromising privacy. For example, in a region defined by a set of zip codes, the ratio of vaccine takers to non-takers should remain consistent before and after data de-identification.
Preserved population integrity ensures that encoded datasets remain useful and reliable for all analytical purposes without the privacy risk.
Statistical Integrity
Statistical integrity ensures that the statistical properties, like mean, standard deviation(STD), entropy, and more of the original dataset are preserved in the transformed data. This integrity allows for accurate and meaningful analysis, projection, and deep mining of insight and knowledge. It includes:
- Preservation of statistical properties: Mean, STD, and other statistical measures should be maintained. Ensures that statistical analyses yield consistent outcomes through cross-transformation
- Accuracy of analysis and modeling: Crucial for applications in machine learning and AI modeling, like user pharmacy visiting projection and visiting
Maintaining statistical integrity is essential for several reasons:
- Accurate statistical analysis: Analysts can perform statistical tests and derive insights from the transformed data with confidence, knowing that the results will be reflective of the original data.
- Valid predictive modeling: Machine learning models and other predictive analytics can be trained on the transformed data without losing the accuracy and reliability of the predictions.
- Consistency across studies: Ensures that findings from different studies or analyses are consistent, facilitating reliable comparisons and meta-analyses
For example, in the healthcare industry, preserving statistical integrity allows researchers to accurately assess the prevalence of diseases, the effectiveness of treatments, and the distribution of health outcomes. In finance, it enables the precise evaluation of risk, performance metrics, and market trends.
By ensuring consistent statistical properties, Statistical Integrity supports robust and reliable data analysis, enabling stakeholders to make informed decisions based on accurate and trustworthy insights.
Ownership Integrity
Owner means an entity that has full control of the original data set. Entity usually refers to a person, but it can also mean a company, an application, or a system.
Ownership Integrity ensures that the provenance and ownership information of the data is preserved throughout the transformation process. The data owner can perform additional new transformations as needed in case the scope/requirement is changed.
- Data ownership: Retaining ownership is crucial for maintaining data governance and regulation compliance.
- Provenance: Reserving the data source origination plays an important role in the traceability and accountability of the transformed data.
Maintaining ownership integrity is crucial for several reasons:
- Regulation compliance: Helps organizations comply with legal and regulatory requirements by maintaining clear records of data provenance and ownership
- Data accountability: Since the transformation is project-based, it can be designed to be reusable or not reusable. For example, different purposes for data analysis and/or model training may transform data accordingly with different data subsets of its origin without cross reference.
- Data governance: Supports robust data governance through its lifecycle to avoid unnecessary or unintentional reuse
- Trust and transparency: Builds trust with stakeholders by demonstrating that the organization maintains high standards of data integrity and accountability; Users of the transformed data can be assured that it comes from the original owner.
In healthcare, ownership integrity allows the tracking of patient records back to the original healthcare provider. In finance, it ensures that transaction data can be traced back to the original financial institution, supporting regulatory compliance and auditability.
Preserved ownership integrity ensures that encoded datasets remain transparent, accountable, and compliant with regulations, providing confidence to all stakeholders involved.
Summary of High-Fidelity Data
High Fidelity Data offers a balanced approach to data transformation, combining privacy protection with the preservation of data usability, making it a valuable asset across various industries.
Specification
High Fidelity Data (HiFi Data) specification aims to maintain the original data’s usability while ensuring privacy and compliance with regulations. HiFi Data should offer the following features:
- Visual integrity: The encoded data retains its original format, ensuring it looks and feels the same as the raw data.
- Population integrity: The transformed data preserves the population characteristics of the original dataset, like distribution and frequency.
- Statistical integrity: The preserved statistical properties ensure accurate analysis and projection.
- Ownership integrity: The ownership and provenance are preserved through the transformation which prevents unauthorized re-use.
Benefits
- Regulatory compliance: Helps organizations comply with legal and regulatory requirements by maintaining data ownership and provenance.
- Data usability: Encoded data retains its usability for analysis, reporting, and machine learning, without compromising privacy and re-architecting the complicated process management.
- Data accountability: Population, statistical, and ownership integrity make data governance consistent and accountable.
- Enhanced security: This makes re-identification extremely difficult.
- Consistency: Supports consistent encoding across different data sources and projects, promoting uniformity in data handling.
Usage
- Healthcare: Ensuring compliance with HIPAA. HiFi Data can be used for population health research and health services research without risking patient privacy.
- Finance: Financial models and analyses can be conducted accurately without exposing sensitive information.
- Advertising: Enables the use of detailed customer data for targeted advertising while protecting individual identities.
- Data analysis and AI modeling: Provides high-quality data for training models, ensuring they reflect real-world scenarios without compromising privacy-sensitive information.